Prompt Engineering Is Where the Magic Happens
Everyone loves to dunk on it, but prompt engineering is the best place to spend your time if you are building with LLMs right now


We’ve seen the memes about prompt engineering. A Real Engineer, as we know, builds a model from scratch or at the very least fine tunes it on a basement GPU setup.

But prompt engineering is genuinely one of those 90/10 skills—spend a little time up front and you'll save yourself a ton of effort, money, and headaches. Spoiler: the reason it’s so valuable is not only because of the output you get out at the end, but because of what you learn in the process. The exploration and immediate feedback of prompts gives you an understanding of the space of model output possibilities. Then you have to decide: is this space good enough or not? There is nothing that will give you a better sense of how good your app will be than rolling up your sleeves and spending half an hour iterating to build a solid prompt.
What this isn’t: a guide on the most advanced prompt engineering techniques. For this, check out chapter 5 of Chip Huyen’s AI Engineer, or Google’s new Prompt Engineering whitepaper.
What this is: a case for why prompt engineering should be the first thing you try when building an LLM app, with specific examples from inContext (including the prompt we are using right now in production).
inContext
inContext is a Chrome extension aimed at language learners that I worked on last year with Alex. If you’re reading an article on the internet in French and stumble on an unfamiliar word, you just highlight it. inContext instantly shows a definition tailored to your level in French—so you can understand it, close the popup, and get right back to reading.1
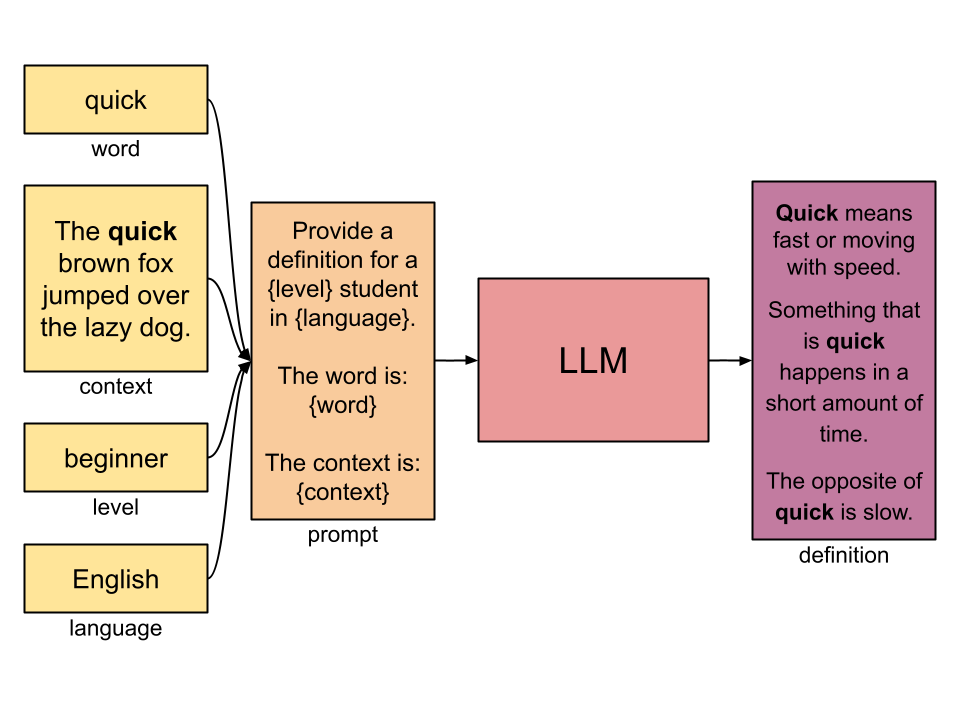
Step 1: Prototype ASAP with One Example
We should establish a definition for completeness: prompt engineering is the iterative process of finding the words (prompt) that will get the LLM to say what you want.
Once I had the idea for inContext, making the first prompt was as simple as opening up a browser window with Anthropic’s Claude Sonnet and testing it. I started with English (more on this later), and picked a random word from a random paragraph from Wikipedia on chess. Here was my first prompt:
prompt v1:
Given a word and context, write the definition of the word using the context to help inform the definition.
word: {word}
context: {context}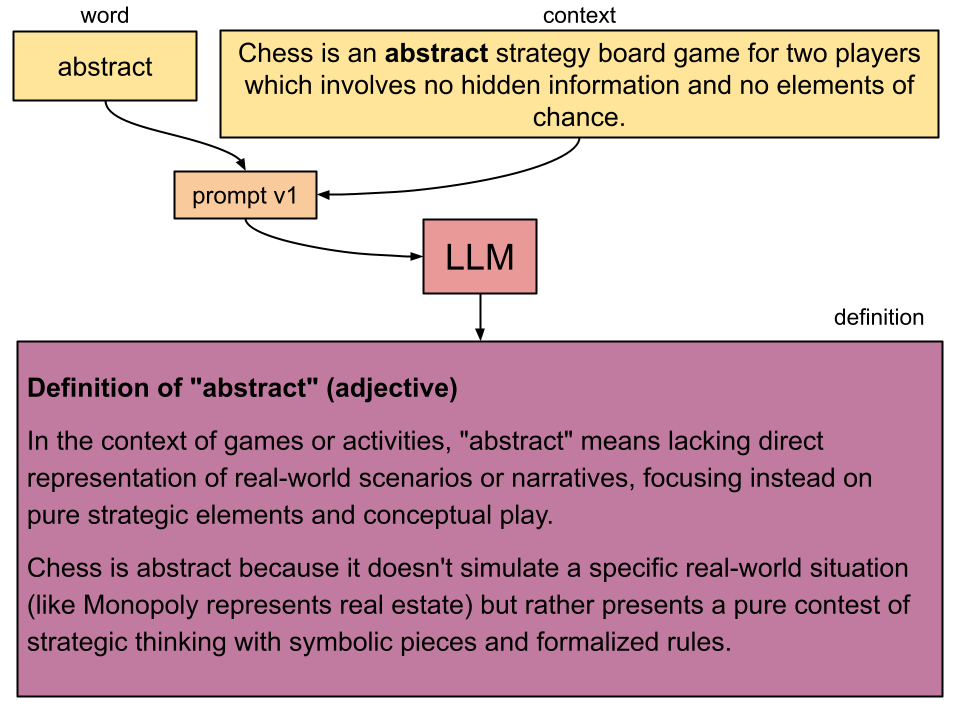
Of course this works well because this is basically what transformers are designed for. So now I started adding things:
level: Your definition should be understandable to a beginner English student.Add a few synonyms (simple).Make sure the sentences are short.Use a few sentences; don't make it overly wordy.Experimenting with techniques like CoT, few-shot, etc. is totally appropriate here. Being familiar with some of these techniques helped me iterate quickly and explore the space efficiently.
Over the course of a couple of iterations, the output started to conform to what I had envisioned. The model and I were aligning the set of assumptions we each had about the task in real time. But at the same time a very important thing was happening: I started exploring in directions I hadn’t initially thought of, like adding synonyms.
Deciding What Good Is
A key component that I glossed over is that I decided to work in English, which is my native language. I did this because it means I can tell right away if the answer is good or not. If you cannot tell right away if the answer is good or not with relative certainty, then you risk making an AI app that demos well but never quite delivers.
What does good mean? This is actually what the act of prompt engineering “by hand” is helping us find out. After a few iterations it occurred to me that in some respects I might not be the best judge of the definitions because I don’t have the point of view of a beginner English student. Of course I could see right away the accuracy and naturalness of the definition, but accessibility to the reader should be an important metric that was a bit more difficult for me to gauge honestly.
Needless to say, once I started testing in languages I know less well or not at all, I could evaluate the output from the more beginner perspective, but I would have to ask for some help to judge accuracy and naturalness. At first though, I did all of the testing in English where I could rapidly iterate and validate.
prompt v2:
What is '{{word}}' in the sentence '{{context}}'?
Please explain it in really short sentences, and very simple English. By simple, we mean a level that is accessible for learners of English at a beginner level.
Also include two words that have a similar meaning.
Please respond in a json that looks like this:
meaning: a representative form or pattern,
synonyms: sample, illustration 
Step 2: Try the Prompt with More Examples
Once I settled on a pretty good prompt for one example, I ran it through five or more examples. The quality of answers seemed to hold up.
This was when I started testing in other languages and different levels. Of course, I had some confidence that the prompt was pretty good since it seemed to work well in English, but this was not guaranteed. Other languages are less well represented in LLM pre-training, and are prone to giving English-y answers that can be very unnatural. My options were to tackle this by asking a smarter LLM with more training in that language (difficult in this case), or asking a native/fluent speaker of that language.
prompt v3:
Can you explain the definition of '{{word}}' to a person who understands only extremely basic English.
Use only simple words and short sentences.
This is the context: '{{context}}'
Please respond in a json that looks like this:
```
{
"meaning": "A computer is a machine. It helps us do many things. It can add, write, and play. We can use it to look at pictures and watch movies. A computer has a screen, a keyboard, and a mouse. The screen shows pictures and words. The keyboard has many buttons to type. The mouse helps to click and move things on the screen. We give the computer instructions, and it follows them.",
"synonyms": ["device", "machine"],
"incontext-info": "In this sentence the computer is a tool the person uses."
}
```
If the word is part of a phrase (e.g. black in black hole) mention that in the incontext-info section.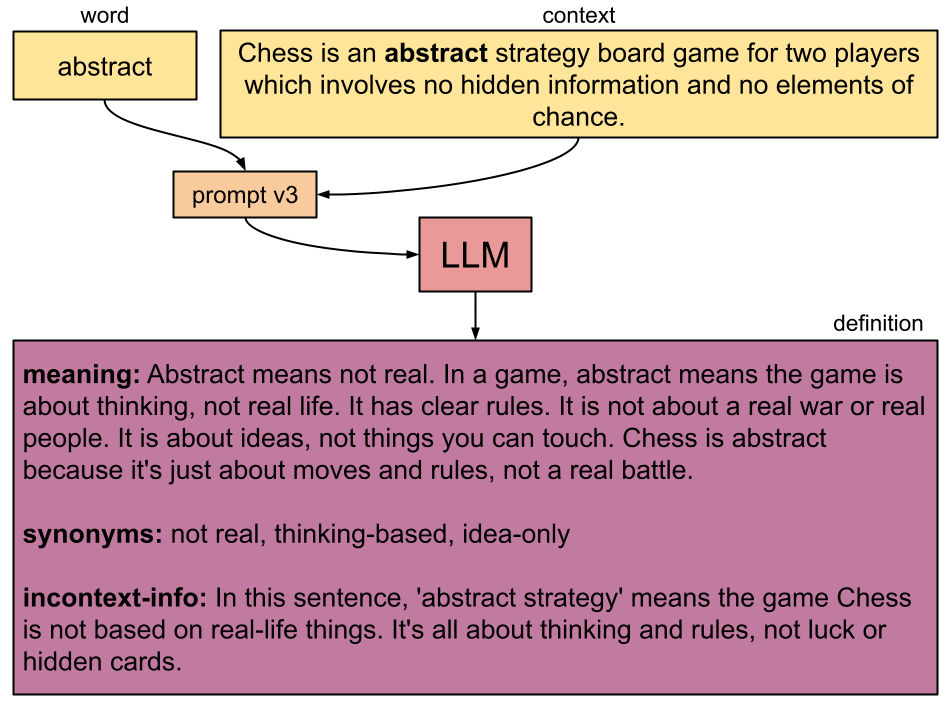
A notable addition in this iteration is the incontext-info section. This was a crucial insight that I stumbled upon while iterating the prompt that really improved the quality of the definitions. For example, in the phrase “don’t be a chicken” I wanted the definition of chicken to be “bird” and the incontext-info to be “coward.” Not separating these two often led to unclear or misleading definitions.
Step 3: Push the Boundaries of the Prompt
Now I needed to find the prompt’s breaking point. I remember looking for deliberately ambiguous words or contexts, and eventually I found a word while testing in Japanese that often gave me lots of problems. It worked only for Sonnet 3.5, and even then, only sometimes!
This word was 円タク, and instead of getting the correct definition, I was getting some hallucinations where clearly the model was trying to guess based on the words and context of the sentence. My options to fix this were the following
Adjust the prompt again (tried)
Try a smarter/different model (there wasn’t a smarter model at the time)
Add in more context using a technique like RAG (this was further than we wanted to go at this stage)
Step 3.5: Polishing a Turd
With hallucinations, here’s what I had to decide: of all the interactions our users are likely to have, what percent am I okay with failure? 5%? And then: are the things I’m testing representative of what our users will likely ask? Given that our word 円タク was an old Japanese word from the Taisho era around 100 years ago, I figured it was relatively unlikely to come up and we were unlikely to solve this through prompt engineering alone.
Another option was to add a traditional dictionary link in the app, or to give the model an out:
If you don't know the definition or it is ambiguous, you should say so.Step 4: Build Out the App
At this point, we were happy with the results of our prompt, so it was time to boot up the IDE and start building out a prototype of the app. Here we learned important things like what using the tool actually feels like, and the complexity of other engineering elements. One caveat here is, if the project is likely to be expensive in time and effort, it’s probably worth taking the prompt engineering a bit further, as described in the next step.
Step 5: Properly Evaluate Model Outputs on a Dataset
This is the Serious Evaluation. The sky’s the limit. There were three things that made this challenging:
Coming up with a representative data set
Organizing and running the executions
Evaluating quality of responses
Using real user data takes care of the first problem. We had a beta version of our tool, and we could see what kinds of words were being looked up. I also added the edge cases I discovered in the first few iterations of prototyping the prompts. For each of these I checked the ground truth manually. This is where we can really discover a true “failure” rate of our app.2
The second challenge of organizing the prompts and outputs is actually the easiest to solve. I used Anthropic’s Evaluation Tool which is built explicitly for the purpose of systematizing evaluation through different versions.3
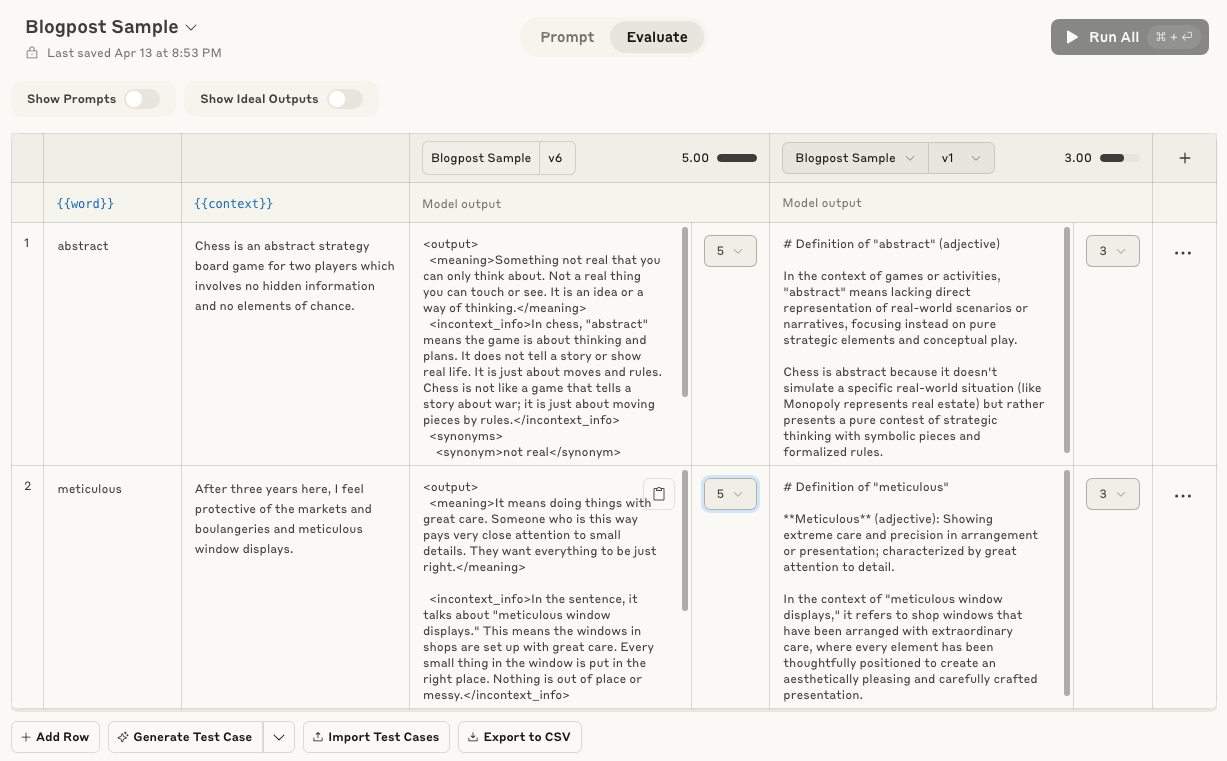
The third challenge of actually evaluating the outputs is probably the hardest. I tried designing a simple rubric and getting native speakers to judge responses by scoring the responses, but this doesn’t necessarily scale well. The rubric was:
Is it grammatical/natural?
Is it simple?
Is it factually correct?
I also experimented with LLM-as-a-judge, though it meant I had to evaluate how good the judges were. As an example, I was comparing version A and B of a prompt to determine which is better, I asked a Claude something like:
Here is a word and its context. I will give you different definitions of this word in this context from two different prompts: A and B. You tell me which prompt did a better job. The target is a beginner language student studying Japanese.
You should give preference for grammatical/natural writing, for simplicity, and for factual correctness. Feel free to include other considerations.
word: {word}
context: {context}
actual definition: {actual_definition}
Definition with Prompt A: ...
Definition with Prompt B: ...It returned:
After analyzing both sets of definitions, I believe prompt B did a better job overall for beginner Japanese language students. Here's why:
1. Naturalness of Text: Both have natural sounding...
2. Factual Correctness: Both definitions match...
3. Simple language: Prompt B uses more straightforward...
4. Consistency: Prompt B maintains a more consistent structure...I did it manually here, but a tool like G-Eval is flexible and made entirely for this purpose. It was definitely worth looking at at least a couple of outputs closely to decide if I agreed with the LLM judge’s take (which means more prompt engineering).
Wrapping Up
The prototyping and thinking that happens when prompt engineering, is probably the most important aspect of designing an application built around an LLM. In our case, investing time early in prompt engineering paid off as it confirmed the feasibility of the project and guided our product design. Only then did we invest in a more significant evaluation structure.
So what is the user prompt we have in production right now? For English, at the simplest level, we have:
prompt v4:
Can you explain the meaning of '{word}' to someone who understands only very basic English?
Please explain this at a super beginner (pre-A1) level.
Use only the simplest words and keep sentences as short as possible.
You may use common words from the top 500 most frequent English words.
Do not use '{word}' in the definition.
This is the context: <context>{context}</context>
Please respond in the following format.
<meaning>The "meaning" should explain the literal meaning in 1-3 sentences.</meaning>
<incontext_info>The "incontext_info" should explain any figurative meanings or actual usage, comparing it with the literal meaning in an easy-to-understand way. If the word is part of a phrase (e.g., 'black' in 'black hole'), mention this here.</incontext_info>
<synonyms>For "synonyms", list common alternatives that a beginner might understand.</synonyms>
{format_instructions}
As models continue to improve, proper evaluations help measure these improvements precisely and efficiently. But what these evaluations may miss, is the intuition for new capabilities and new product directions we gain from experimenting with prompts. These are only earned when rolling up our sleeves and prompt engineering the good old fashioned way.
You might be wondering why people would do this but in the language learning world it’s called immersion learning or making a monolingual transition. The idea is to try to avoid mapping 1 to 1 with words in your native language, and understanding it more naturally within the context of the new language.
Failure in the sense that there we fail to return a quality definition.
Actually, this tool is pretty great. You’ll need an API key to set it up, but it works well for iterating prompts in the way I’m describing in the article. It stores all the prompt versions and model outputs outputs, and saves you time from having to copy and paste all the inputs (word and context) everytime.