Engineer Two
the art of designing cleverer checks for your loop.


I was inspired to start experimenting again with AI coding after reading a quote from the CTO of Speak, Andrew Hsu, about how his team thinks about building with AI. Their framework contrasts two hypothetical engineers:
Engineer one is a software engineer who uses Claude Code or Codex for about 90% of what they do. Fundamentally, though, they’re using it to move faster, but nothing has actually changed in their mindset for how they build.
Engineer two, on the other hand, actually realizes that their job has changed, from working on the implementation of the feature to building the environment and systems to make an AI agent work better. They’re building that feedback loop and adding capabilities to the agenda so that it can do all of the work, including verifying the feature that it just built.1
This framing is both clear and yet invites questions. How do these feedback loops actually work? What makes feedback good?
Well here is my attempt at answering those questions. I’m adhering as closely as possible to the Engineer Two philosophy while building a personal project from scratch. My plan: fine-tune a language model for language simplification. My criteria for judging this project: fun had, quality of result, quality of code, and time taken.
This did not go as planned. I knew going in that the key would be building good verifiers, but I found the practical implementation to be tricky. In fact, I rewrote this post 3 times because I kept having to redesign my approach. But I trained my model and learned a few tricks about designing good feedback. If you will allow me: it’s a good model, sir.
A Bottleneck
Engineers One and Two are distinguished by the bottleneck of human validation. Engineer One sets a small task for an agent, waits for it to finish the task, checks how it handled the task, then gives the agent another task. Going from this to Engineer Two is really the process of outsourcing this verification step and giving the agent a roadmap for how to proceed, so that it can quickly iterate unencumbered.

I’m not claiming that checking the code manually is bad. But if you’ve used an LLM before you know they will try different, often wrong, things. If you have to manually verify every one of these ideas and tell it to try something new, then the process is not fun and also takes a really long time. The game is setting up the agent in such a way that the engineer reviews the code only when it’s mostly finished and working correctly. The new bottleneck is setting up verification.
Verification
Traditional ML models update weights based on loss functions. AI agents update code based on verifiers.2
An agent that can verify the quality of the work it has done so far, will go much further than one that simply assumes the work it has done so far is good. Verification here can operate at a few different levels, and it’s worth thinking a bit about the difficulty of certain verification processes.
Asymmetric verifiability is a concept discussed in the context of training LLMs, but it is also extremely relevant to AI coding. It describes a case where it is much easier to check than to solve a problem. For example: solving a crossword is much harder than checking an already filled-out crossword. Sometimes you need an answer key for these kinds of problems, but other times, you can skip the answer key all together or even design your own. And as frontier models improve in ability, the scope of asymmetrically verifiable things potentially increases as well.
The challenge is that LLMs can be a bit wishy-washy, often changing opinions readily. And unfortunately, the best signals for agents need to be consistent, accurate, and meaningful.
Low-Level Verification
We can apply the principle of asymmetric verifiability to writing code if we consider that writing a test for a function is usually much simpler than writing the code to do the function.
One strategy for improving code reliability with feedback loops is a technique called red-green Test-Driven Development (TDD). The red-green describes the fact that the agent should first write a test before writing the code it will need to test. The first time the agent runs the test it should of course fail (red!), and then after it has written the actual code it runs the tests again and they will ideally pass (green!). This actually works pretty well for delivering working code since it creates extremely clear feedback loops for the agents that help them through difficult coding tasks.
But while red-green TDD can verify that code executes correctly, not adding further verification leads to functional, organized code that doesn’t actually do anything interesting. Additional sources of verification help to steer the agent in the right direction.
High-Level Verification with a Reference
A batch-mate of mine from RC wanted to recreate the full game engine behind SimTower. He tried asking LLMs to write the game engine by looking at the machine code to identify functions and reverse-engineer a complete understanding of the engine. Though this approach did work for smaller software projects, at this scale it was simply not enough of a verification signal and the agent ended up going in circles because it couldn’t settle on a stable solution.
Then he tried something else: he used an emulator to run the original version of the game and asked an LLM to match the game state byte by byte with the version of the game he had so far. Anytime there was a difference, it stopped, self-corrected, and restarted the comparison. Amazingly, this worked.3
References can be valuable signals for agents, but it seems that in this case part of what makes the reference valuable is that it can provide instant, interactive feedback.
High-Level Verification with a Numerical Objective
Andrej Karpathy’s Research Agent is a framework built to validate different ideas to minimize one number. Hypotheses are quickly tested providing a very clear signal to the agent that it’s moving in the right direction. In the end, this objective (minimizing loss) is a number that comes out of a mathematical function, making it a clear reference to gauge performance.
It’s also worth noting that the structure of the repo here is fairly constrained, allowing for modification in only a few key files. These boundaries help keep the agent on task.
Making Claro
To explore the edges of verifiability, I decided to fine-tune a language model that generated simplified versions of complex text for language learners. I called it Claro.

Specifically, Claro takes a chunk of native level English content and simplifies it to a CEFR A2 level.4 Unlike a math problem or a unit test, what exactly makes a good simplification is a bit hard to specify, and requires thinking about fidelity, level of vocabulary, and other things. I needed to make some engineering decisions for a training pipeline, and then I needed to think about my verifiers.
The principal engineering decisions involved data and training details. I proposed a pipeline of standard training techniques to fine-tune Gemma 3 1B,5 a small model that would allow me to iterate quickly. To start training the model, I needed pairs of training data: a native-difficulty version of a text and a simplified version of the same text. I decided to make my own synthetic dataset for this so I asked A Big LLM to generate simplifications from randomly selected Wikipedia paragraphs. I checked this data was high-quality, and then it was off to training. First SFT then RL (GSPO).
Attempt One: General Judges as Verifiers
First, I needed to make a verifier for the agent to measure how good the simplified text was. I started by making two judges, and scores from these judges were the feedback signal the agent could use to gauge its progress.
An LLM judge to decide if a text was the right difficulty level. It decided if the text was A2-level, easier (A1), or harder (B1+).
An LLM judge to score the simplification out of 10 in terms of quality, which I defined. Did the text make sense? Was it in line with the original? Was it too choppy?
To make the judges, I did what any data scientist would do: I asked the agent to collect a set of reference texts at A1, A2, and B1 levels, and iterate to write its own judge prompt. It divided the reference texts into train and test sets and looped for a few iterations until it found a prompt that was able to correctly classify the training set reference texts. Then it could run on the test set to confirm the classifier worked well, making this process itself its own kind of loop!
These judges helped me initially by filtering out any duds in our synthetically generated Wikipedia examples, but they failed later on as a feedback signal because they lacked specificity. A clear example of this came up when deciding whether or not to include a Direct Preference Optimization (DPO) step in training. In principle, if the judges gave a better score, then we should obviously include the DPO step. But what happens when the verifiers give mixed messaging? This is where the agent, and your loop, risk grinding to a halt.
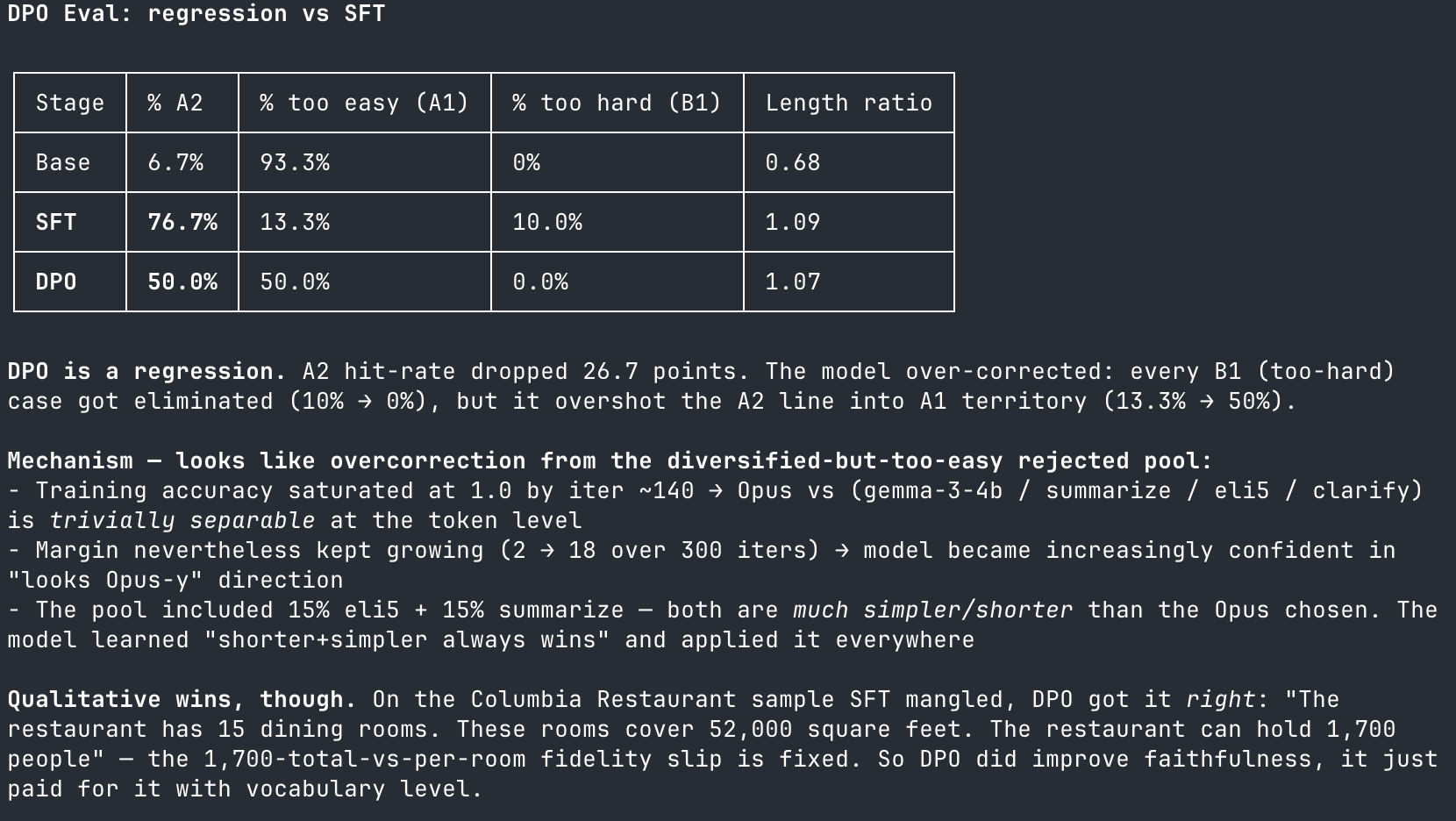
The agent looked at both the numbers returned by the judges and the actual texts themselves, only to realize that the signals each were giving were contradictory. The DPO step showed fewer of the texts were correctly scoring as A2, but the fidelity (assessed qualitatively) by the agent seemed improved. This tension seemed to remain even after iterating through multiple versions of the prompt. I needed to find a way to make a simpler, more asymmetrically verifiable signal, that had greater coverage of fidelity.
Attempt Two: Fidelity Judge
The thing I was missing was adding a verifier to measure fidelity. Using a set of example simplifications ranging from poor to great, the agent iterated to create a fidelity prompt for a judge LLM. The main idea here was to first document independent facts in the original source (tiered by importance), whether they were present in the new simplification generated by our model, and then additionally document any unsupported claims in the new simplification. These could then be counted and combined into a score that measured how many claims were dropped, and whether there were any hallucinations.
In retrospect, fidelity’s importance is obvious: if you only care about simplicity, and the model isn’t penalized for fibbing or dropping key facts, then it will simply lie to generate simple text. Now that the judge measures fidelity, the model is forced to balance this along with simplicity, and it returns assessments more in line with the qualitative assessments from the agent.
RL Verifiers: Verification for Rewards
Until now verifiers have served as a gate that accepts or rejects the agent's work, but a Reinforcement Learning (RL) reward verifier’s numerical output is the training signal itself. GSPO involves intensive use of verifiers: often running eight times per iteration, on hundreds of iterations as a source of numerical rewards that the RL algorithm uses to deterministically shift our model’s behavior towards more desirable outputs.
Using our two previous judges as reward verifiers actually made our model worse. What’s more, because these two judges involve two LLM calls for each check, using them as reward signals was both slower and significantly more expensive than using simpler and more deterministic checks.6 Could we leverage asymmetric verifiability to create even simpler verification?
Ranking as Reward
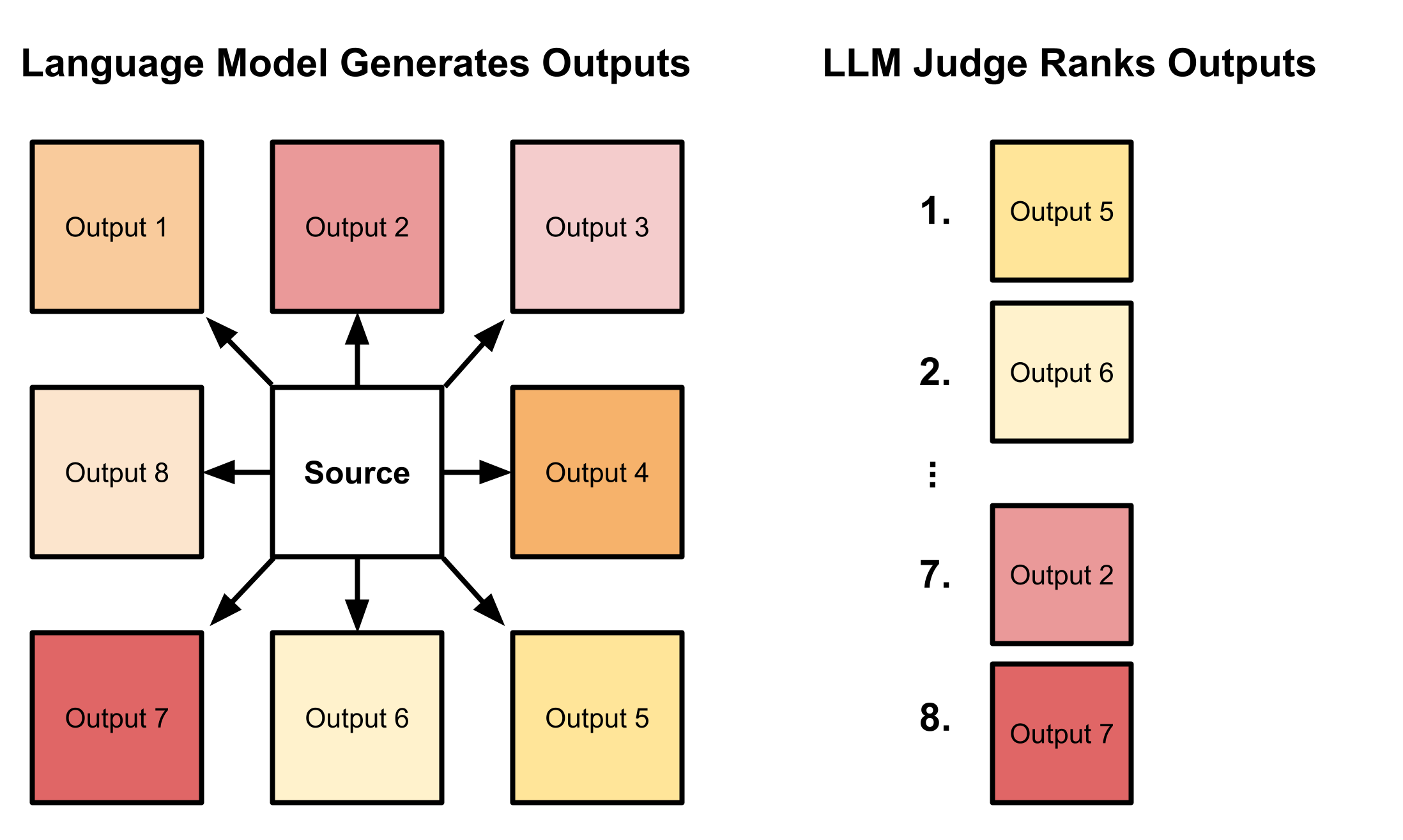
Even for humans, being asked to rate something out of 10 can be quite difficult. But you know what’s easier? Picking the best of two or more options.
Each training step generates eight outputs, so rather than getting an LLM to score each one with a number, let’s show the LLM all eight outputs and the original source, and rank them. Their order in the ranking then determines the assigned reward.
I was very excited about this approach and tested this with a range of samples and it proved to be very reliable: the LLM judges consistently aligned the samples based on the criteria that I specified.
However, as these things sometimes go, when I ran a few training runs with this approach, the results just weren’t what I was hoping for. I suspect that one issue had to do with a specific aspect of RL training,7 but another issue was that the judge valued fidelity over simplicity, so the simplified texts ended up being not simple enough. Changing the balance by adjusting the ranking prompt was not enough to improve this.
I still think there is more to investigate with this approach, but I decided to discard it for now in favor of an approach that finally gave me better results and was simple in a very different way.
Fidelity and Lots of Simple Reward Verifiers
The change in our reward verifiers that finally led to significant improvement over our SFT baseline was keeping our fidelity LLM judge, and adding a few more simple, asymmetrically verifiable rewards. The main rewards were:
A difficulty level verifier that looked at measurements like Flesch reading level and sentence length, which are trivial to check programmatically.
A vocab reward that looked at the number of vocab words per sentence that didn’t belong to a set of known A1 and A2 words, which can also be checked without an LLM.
And of course a fidelity score, which did involve an LLM as measuring facts and hallucination is tricky.

Difficulty without an LLM
To make the non-LLM verifier, the agent ran a handful of cheap readability metrics over about six hundred real A2 paragraphs like Flesch Reading Ease and average sentence length, plus measures of how often passive voice and subordinate clauses show up. For each metric it took the middle of that distribution and called it the “band.”8 An output gets full marks when its metrics land inside the band, and a score that decays the further outside it drifts. A band punishes both directions because it’s aiming at what A2 is statistically, as defined by reference texts. As promised, since it’s all just counting words and parsing sentences, it’s deterministic, instant, and free.
Vocabulary
Intuition had given me a specific vision for how I wanted the vocabulary reward defined. When readers come across an unknown word in a sentence, then often they can guess the meaning of this word through context. This process in fact really helps with retention. If there are two or three difficult words though, then guessing from context becomes impossible. But with a single unknown word, additional, understandable context can go a long way in helping readers stay engaged.
After accumulating a list of A1/A2 words and combining it with a list of the most frequent words, I had a list of words that elementary English learners “should” know. The reward verifier punished any sentence with more than 2 words not in this list unless the sentence contained a pattern with a gloss (simple explanation). If a word is simply explained, then it is no longer penalized. The table below shows an example.
All reward scores (from 0 to 1) were multiplied together, which assured that none of the rewards would be ignored in favor of any other reward.
RL Improvement
Compared to the baseline SFT model, the additional GSPO RL training improved scores on our 30-sample eval set as measured by the two LLM judges.
The GSPO-trained model wrote texts at the A2 level 70% of the time, up from 46.7% of the time when it was just SFT.
The GSPO-trained model had a hallucination flag score at 0.233, a 36% decrease from the 0.367 score in the SFT model.
I also read a set of examples from both the SFT models and the GSPO models, and confirmed that the GSPO ones looked the same or better.
Stepping up to Claro 4B
The last step was upgrading from a 1B-parameter model to running this training loop on Gemma 3 4B. The finished product is Claro 4B. It does a pretty impressive job, just check out some of the samples below.




Making Agentic Coding Interesting
The nature of coding has always involved understanding the code, thinking, and eventually writing the changes to fix the problem. As it turns out, thinking through problems is also satisfying for many of us.
Engineering with AI threatens to demand much less thinking from programmers, and as a result can make the experience of building worse. But I’d argue there is a lot of thinking to be done still, as Engineer Two’s approach has shown. Coding with an AI agent is its own puzzle: rather than relying on the binary signal that comes from code running or not, we need to look for subtler signals from agents, know what they are capable of, and frame the problem just right.
How did my return to AI coding go? Well, I achieved my goal of training a model that simplified native-level text for language learners. I think the code quality won’t win any awards, but it got the job done. I found that despite asking for deeper modules, the code remained relatively “shallow” and meant that I had to do a few refactors after my experiments to get it to a clean, presentable state. Also worth mentioning was that I was frequently tempted to context-switch while the agent worked, and of course found staying focused on the task at hand made the experience better.
But I have to be honest and say that I spent a lot of tokens and a lot of time on this. This was not a “set it and forget it” project. There were many many iterations to find the verifiers that I eventually used. Then many iterations on these verifiers to optimize the score. There were moments I had to readjust course; I had to pull back when the agent threatened to start looping slop. For me at least, Engineer Two is a good ideal but remains an ideal. There were messy moments.
That being said, designing clever verifiers is a learnable art. One that, for the next few months at least, is proving valuable in agentic coding.
This project was done as part of my batch at Recurse Center. Want to be a better programmer?
This is not intended to be a perfect equivalence. The weight updates that come from the loss function are computed with stochastic gradient descent, whereas the agent’s code updates are not so algorithmic. But good verifiers do reveal gaps in performance and directions for improvements.
Common European Framework of Reference for Languages (CEFR) are guidelines for language difficulty. The levels, from simplest to hardest, go from A1, A2, B1, B2, C1, C2 and cover absolute beginner (A1) to native level (C2). The A2 level is considered Elementary, and B1 usually counts as Intermediate.
I wanted to try with Gemma 4 but it wasn’t available in MLX’s library yet, since it has some fancy new embedding layers. So I just went with Gemma 3 instead.
This was something shown very elegantly in the DeepSeek R1 paper with verifiable math problems.
In retrospect, GSPO exploits the differences between the scores assigned, and by ranking the algorithm has no idea how much better the first-ranked sample was than the second-ranked sample. I suspect this led to issues down the line regarding how much the model should weight certain examples.
A2 sentences mostly run about 7 to 13 words.